终于可以稍微停下来不用加班了,这是我进过得最轻松的一个双休,总算是可以放下心来好好的调整一下。话说我三月份开始在时代财富公司上班,那怎一个忙字了得?别以为你是刚进公司新员工就要有一个适应环境的过程为由,工作上可以给你放宽一下,刚进公司Earth给我一个事例,是公司.Net框架的应用,因为我们公司是有自己的开发框架(Studio),几乎所有项目都依赖此框架进行开发的,所以我进了这个公司第一件事就是了解整个框架的开发使用流程,大概花了半天时间来看,然后又花了约两天时间用此框架做一个产品及其分类的增删改查的简单例子,交工!感觉用起公司那个Studio框架还行,有自己的分页控件,用工具自动生成实体及基本增删改查类,使用反射DataTable来填充实体值并返回(泛型数组),然后对数据库的访问是以接口的方式提供,即创建的所有ADO.Net对象都是使用接口根据Web.Config配置最终来决定实例化的子对象(SQLServer或Oracle数据访问对象),此种方式略有不同于PetShop的工厂模式,PetShop里有一层sealed类根据Web.Config配置来决定接口实例化子类(SQLServerDAL或OracleDAL),所有DAL都单独实现了接口里所有方法等,并是针对自身的差异来一一详细实现,如SQLServer和Oracle的TSQL语法可能会不一样,譬如Oracle没有自增编号只能用序列,或传递参数使用":="等,这样来根据数据库的不同而分别进行实现确保万无一失!但是这样你会比较麻烦,比如你写个订单的处理的DAL,你在SQLServerDAL里必须完成订单的增删改查的方法,你在OracleDAL里也必须完成订单的增删改查的方法,而我们在实际项目中应该也是二选其一吧,要么SQLServer要么Oracle数据库,仅当数据库相互移植的时候才会觉得写了有用,但当客户移植数据库的时候我想就不单只在Web.Config文件内改一下配置那么简单了吧?所以我觉得PetShop这种模式大家在实际应用的还是比较少的。那么使用接口来创建ADO.Net对象具体又是如何来实现根据Web.Config文件内配置访问不同的数据库呢?请看如下代码:
上述所示代码是根据不同DatabaseType数据库类型枚举值来创建数据库连接对象,当然这个DatabaseType也可以从Web.Config配置文件内读取,根据不同DatabaseType我们还可以创建IDbDataParameter、IDataReader、IDbCommand等对象,返回的为接口实例,而我们在使用的时候便是用接口代替平常SQLServer或Oracle的ADO.Net对象。一个较完整的数据库查询如下:
如此一来,我们便可以根据不同DataBaseType来执行查询,以此类推我们可以使用传递接口的方法来实现增删改等,DataBaseType枚举值决定它执行实例化的子对象,我是觉得这样来执行不同数据库的操作很是方便,不知大家对我的这种方式是否认可?公司里面的Studio里实现不同数据库访问跟我上面写的又有写区别,它里面有个IDbExecutor接口类,注释为数据存取器(执行者)接口,里面规范约束了所有增删改查的方法也都是返回接口类型,它有三个实现类OleDbExecutor、OracleDbExecutor、SqlDbExecutor,是针对不同数据库访问的具体实现,相当于SQLHelper的功能,这个时候每个实现类已明确了各自访问数据库的类型,但是它们一些方法的参数接受的仍然是接口类型,因为只有这样在调用的时候对不同数据库的访问的才能做到通用性,只传递公共的参数类型,那便是接口。所以总体来说是大同小异!
那么,是不是这样去实现对数据库访问层就真的会通用了?不完全是!我们似乎还忘记了一个最重要的东西,那就是每种数据库会有些不同的TSQL语法。就如上面所提到Oracle没有自动增加编号只能用序列,对于这点我们公司好象数据库有个表来存其他表的当前编号,有个存储过程专用来取某个表的当前编号,相信为了是实现兼容Oracle的序列吧,但是我打开那个存储过程一看,发现有一个非常严重的问题:那就是没有处理并发!因为我以前也是用这种方法,就是直接取当前表的编号,然后修改编号为+1,以前和同事做过一个测试,就是我们两个人同时调用取表当前编号的那个存储过程,然后复制在查询分析器同时执行上千次,2个人一起按F5执行,结果发现2个人里有取了相同的编号!所以说使用这种方式做没一些处理是不行的,应该取时加上事物锁。
加上以上事物处理后,经反复测试未取到相同的编号了。我们还使用同样的方法测试取@@identity,及对同一个表进行插入数据后取当前的自动增长编号,同样强度下使用@@identity未发现取到相同的自动增长编号,所以说使用@@identity并不会出现并发现象,SQLServer是经过处理的,所以没什么其他特殊的要求就使用@@identity自动增长编号吧,在这值得一提还有uniqueidentifier类型,SQL里面使用newid()来产生,程序里也可使用GUID来生成,几乎也不会出现相同情况,而且可以在SQL或在程序里方便获取,导数据也方便,听说比int类型主键做索引不会慢!
好象说得又有点走题了,继续回到不同数据库的主键产生的话题上!SQLServer插入记录的时候自增编号列不需要指定,使用@@identity返回,而mqsql则需要指定自增编号为default,我们在SQLServer的条件判断可以轻松的使用case when [field] = 值 then 1 else 0 end,而Access的语法应为iif([field] = 值,1,0);Access取当前时间为now(),SQLServer为getdate(),Oracle则为SYSDATE,而mqsql则为CURDATE()。所以,我们在切换访问不同数据库时候就不单只改变Web.Config配置文件那么简单了,我们得注意一下我们执行的TSQL语句了,因为每种数据库的SQL语法可能会略有差异,但是绝大部分的数据库的DML语句都通用,所以我们就得尽量取同求异了,比如时间我不在SQL语句里用函数获取,而在程序里面获取当前时间作为参数传入进去,这样使每种类型的数据库都能通用,如此一来我们在切换到另外一种数据库去执行该SQL语句也没问题了。
又说了大堆废话回到主题,刚进公司约三、四天后,就忙得个昏天黑地的加班,我新进员工也未能幸免。一般是每晚都要加到10点左右,但是后来一天比一天加得晚,我记得我最晚打卡的一次是过了凌晨,每天没完没了的加,连周六整天也要加,就一个字累啊。让我们忙的焦头贴儿的是最近才中标的一个门户网站项目—,它是下佛山新闻中心、佛山日报社、佛山电台搞的一个网站,算是佛山市政府的门户网站,金额达二百多万元人民币,是我们公司目前接的最大的一个网站项目,并且这个项目来得很急,给的时间也很短,只给一个月的时间,对,就一个月的时间必须出来一个门户网站,我们公司做技术的合起来大概也只有上十来个人,做设计的应该也只有寥寥可数的几人,在这短短的时间内完成一个这么大的门户网站几乎不可能,但我们却完成了这个不可能艰巨任务!
 | 呵呵,来插一张我的同事们做完这个项目后QQ个个性签名的截图吧,看看,可想而知这个项目对我们的影响,甚至是对我们公司的影响是多么的大。对于我来说这次最大的收获是项目经验,能有机会参与这种门户网站的开发,并且学到了不少东西,体能相信也锻炼提升了不少!^_^!!!为什么这么说呢?因为这次我还被公司派到佛山传媒集团客户那边工作,哎,甭讲了,你别以为出差就是住酒店享福了,到那边工作可是番苦差啊。出差佛山工作一个星期,除开一天晚上没有加班,其余每天晚上基本到凌晨过后才走,还有一天晚上是通宵达旦,第二天继续工作... 从来没有如此煎熬的工作过的我,那几天昏迷得不知是如何度过来的,还好去客户那边工作还不算特累,客户那边工作环境也很不错,吃的也不愁,就是要加班工作时间太长了,本来在那边就准备写篇博文的,后来发现真的难写完,现在那篇还空在那里待续呢! |
佛山新闻中心

门户网站的形成—CMS内容管理系统
这么大一个门户网站,N多个栏目,每个栏目下又有N多个频道难道都是靠我们技术一行行代码来实现动态输出的?答案是当然不会是!首先,项目的给你的时间不允许,如果说你每个页面都需要编码的话,那么你几百个页面不可能在一个月内完成的,这些页面的大小可不只就几KB的内容,而是每个页面都是几十KB,项目在那个时候也不能冒此风险。再着,作为门户网站内容多而访问速度要快,如果采用编码来实现又将需要考虑诸多网站性能运行效率问题。
完成并非偶然,最终的解决方案为采用CMS内容管理系统。作为一个传媒、新闻、政府信息发布的网站,用得最多的就是类似一条新闻信息的录入后在进行发布,如果你的网站完成了这些信息前台的查询显示,那么你的网站已完成了70%,CMS内容管理系统便充当这些信息的进行有条不紊管理的工具。好象在中标时佛山客户那边已经决定要求使用CMS内容管理系统,我们采用的是(2008 北京拓尔思信息技术股份有限公司)的WCM内容协作平台。这个TRS可不是省油的灯,除了有些功能实现不了外,要的钱也不少!好象我们做这个网站买它那个系统就要二十来万,不过的它的有些功能确实强大接近完美,且已经很成熟人性化,值得我们借鉴学习。
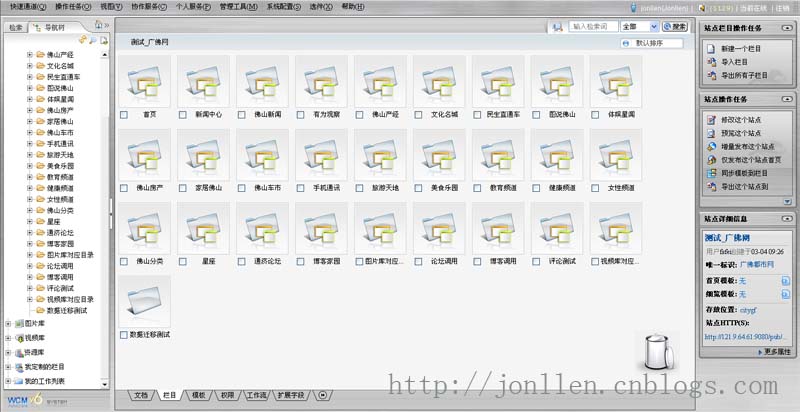
对于一个CMS内容管理系统,信息的发布及展示是至关重要的一个核心环节,TRS采用模板技术,将所有频道、栏目、信息内容页页面根据所套用模板发布为静态页面。静态页面的生成完全根据模板的定义,所以我们工作就转嫁为写模板。它的模板里用于动态生成有它自己的一套标签,称之为TRS置标,它的写法也很简单,跟HTML标签的写法差不多,有属性可以进行嵌套,实现的功能类似于.Net里那些Repeater数据绑定控件,但它读取的数据大部分都是根据指定的ID,而ID则是频道或栏目的唯一编号,一个简单的例子:
上述所示代码完成的是循环输出10条佛山产经的文档,怎么样?是不是用起来很方便!它那些置标还有很多的可选属性,如field="doccontent"当前数据库输出显示字段,autolink="true"是不是自动产生文档链接,num="240"设置输出显示的文字长度等,如果是文档列表<trs_documents>还有where和order等属性,是直接能根据数据库表字段加条件或排序。
对于栏目和频道,也有对应的<trs_channels>置标来输出,那它还提供一个当前位置<trs_curpage>的置标,你写在不同频道模板里能显示的当前所处的位置,相当于一个站点地图的功能。另外,它还提供文档附件(图片等)、滚动新闻(某个时间段)、相关新闻(自动配置到改文档的相关文档)、简单的条件判断输出等置标,方便实用。模板内动态输出的内容就用这些置标代替就有了,基本上能解决大部分页面内容的输出显示。
模板:TRS把模板分为三类概览、细览和嵌套。所谓概览模板顾名思意,是页面整个概览所需套用的一种模板类型,如每个频道栏目的首页,大部分文章新闻都只显示一个标题,然后点链接进去才是看到具体文章的内容,此时这个页面应用的便是细览模板。针对某一个栏目或频道而言,它一般应需制作三个模板,首页、内页列表页、栏目或频道下文章的细览页,有些栏目或频道可能没有专门的首页就由列表页代替。列表页其实就是显示当前栏目或频道的所有子栏目频道,并各自显示头几条文章,并且都有more+链接以显示更多,链接跳转的就是到该子栏目频道的首页,如果无首页则一般应用显示列表页,依此循环递归,采用这种方式我们可以根据more+链接将看到一层层深入到子频道,很好的衔接而没有出现过一个死链接,不管你的栏目或频道有几层!而嵌套模板则是类似与.Net里面的用户控件,它是为了做到代码的重用性,比如我们网站的头部就可以做成一个嵌套模板,然后我们能分别在概览和细览模板里引用。
栏目或频道一般需要套用首页和细览模板,其子栏目频道如无特别制作的主页则全部分别继承引用内页列表页和细览模板,文章应该是隶属于某个栏目频道,它无需单独每篇套用模板,而是应由所属栏目频道决定。那么我们在发布某一篇文章的时候则是根据所套用的细览模板重新生成改文章的内容页静态文件,而我们一般发布某个栏目或频道则是指套用概览模板生成该首页,TRS还提供增量发布、计划任务定时发布等。
TRS将各种不同类型的文档单独分开来,有文字库(下面为网站>>栏目频道>>文档),是最主要的部分、文章所存放的位置;还有图片库专门用来保存图片,并自动产生几种常用的规格大小的图片;以及视频库、资源库等,各司其职,并且相互能很好的调用。这样,各部分有序的组合起来,将栏目或频道及文章统一发布,并自动根据设置的存放位置进行发布静态文件记录保存其URL链接地址,一个门户网站的便这样生成了。
我是没有用过其它的CMS内容管理系统,听说网上还有一些免费开源的,不知其它实现得是怎样的?不过我是感觉TRS的这个系统是不错,它把所有的页面根据模板全部生成静态页面访问速度那自然是没得话说,但殊不知这样做造成服务器上的文件太多而会产生一些影响,这个还得待网站录入上千万条以上数据后来考验了。
注:以上、、、等微标版权属于原公司持有,此处仅当引用。